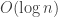The voice has stopped. It probably sees we’re working hard on this problem of his.
We’d like an algorithm, that given an array of some stuffs and a number, will give us a specific and unique permutation of that array, corresponding to the number. As if it accesses some array of precalculated permutations.
Maybe we should do just that. Calculate every permutation, keep that in an array, and in constant time fetch the right permutation. The answer is no. If you followed here from the first part you should know by now, that for an array of size 100, we couldn’t keep all its permutations on any computer. Ok, maybe we’ll just use the second algorithm to generate all permutations up to that requested permutation index, and return the last one? The answer is again, no. Given that 100 element long array, we have about 10156 permutations to choose from. One could choose a very high number, and to calculate all those permutations could take a lot of time. Years actually, millions of millions of years. We wouldn’t want that.
Up until now, I haven’t talked about how we actually calculate a permutation. The first algorithm was given without explanations, and the second one was practically a re-implementation of the first without recursion (without a formal recursion anyway). Given the last paragraph, it seems we need to think this whole thing over, and not rely on the last post.
So how do we calculate a permutation? Think about an array of 4 numbers, 


That algorithm does not do any kind of randomizing. Formally, we call it deterministic. As such, it’ll output the same sequence of permutations every time. What makes the n’th permutation the n’th permutation? We’ve already answered that, it has chosen a specific place to swap the first place with on the first recursion level, and another place to swap into the second place on the second recursion level and so on. Given a number, n, we need to find a way to calculate those swaps at each level. If we knew those, we could redo them, and generate the n’th permutation.
Let’s give our algorithm that 4 element sequence. We notice that on the 3rd recursion level, the decision for the third place, on the first iteration it doesn’t swap with the fourth place (it swaps with itself), and on the next iteration it swaps with the fourth place. These are the only options it has. Between those two iterations the algorithm prints out a permutation. So it is clear that the third place is swapped with the forth on every odd permutation number, and not swapped on every even permutation number. So for the n’th permutation 
No matter what choice the 3rd decision made, the 2nd decision has made its choice: The decision with whom to swap the second place with. Further more the 2nd decision has 3 options. So for a the n’th permutation, 

Another way to look at it is this: Draw a tree that has 4 nodes connected to its root (put them on the same level), and each such node is connected to 3 more nodes (put them on one level too), and each of those connected to 2 nodes (again on the same level). This is our decision tree for this example. Each leaf (a leaf is a node that only has a parent node, like the ones on the last level) represents a permutation. You could number those, starting from the left and ranging from 0 to 23. Each level is a decision, or recursion level. And each connection (an edge) is an option. The first decision has 4 options, the second has 3 and so on. You can easily see that the 3rd decision can be deducted from the parity of the permutation number. And for a specific permutation number, by dividing it in 2 the 2nd decision can be deducted, and so on.
I hope we got it. It’s easy to extrapolate from that an algorithm for any sequence. There is one last thing before I’ll show the code. Our function should be able to take very large numbers as input. Fortunately, if a proper implementation is required, one could use the freely distributed (as in speech) GMP library for arbitrary precision math. It is very easy to compile, use and also has c++ extensions. I, for brevity and clarity reasons, won’t use it here.
#include <cstdlib>
#include <cstdio>
#include <cstring>
class RamPerm {
public:
RamPerm(const int *arr, const int length);
~RamPerm();
int *get(unsigned long index);
private:
int m_length;
// the original array, the working array and the decision array
int *m_arr, *m_getArr, *m_decArr;
};
int main(int argc, char **argv) {
if (argc != 2) {
printf("usage <exec> <N>\n");
return 1;
}
int permLength = atoi(argv[1]);
if (permLength <= 1) {
printf("N should be greater than 1\n");
return 1;
}
int *arr = new int[permLength];
for (int i = 0; i < permLength; ++i)
arr[i] = i;
RamPerm rp(arr, permLength);
int *bla = NULL;
int p = 0;
while ((bla = rp.get(p)) != NULL) {
for (int i = 0; i < permLength; ++i)
printf("%d ", bla[i]);
printf("\n");
++p;
}
return 0;
}
void swap(int *a, int *b) {
if (a == b)
return;
int temp = *a;
*a = *b;
*b = temp;
}
RamPerm::RamPerm(const int *arr, const int length) : m_length(length) {
m_arr = new int[length];
m_getArr = new int[length];
m_decArr = new int[length];
memcpy(m_arr, arr, length*sizeof(int));
}
RamPerm::~RamPerm() {
delete[] m_arr;
delete[] m_getArr;
delete[] m_decArr;
}
int *RamPerm::get(unsigned long index) {
// populate the decision array
m_decArr[m_length - 1] = index;
for (int i = 2; i <= m_length; ++i) {
m_decArr[m_length - i] = m_decArr[m_length - i + 1] / i;
}
// if last divide is more than 0, than index is out of bounds
if (m_decArr[0] > 0) {
return NULL;
}
for (int i = 0; i <= m_length - 2; ++i) {
m_decArr[i] = m_decArr[i + 1] % (m_length - i);
}
// copy original array to working array
memcpy(m_getArr, m_arr, m_length*sizeof(int));
// permute array
for (int i = 0; i <= m_length - 2; ++i) {
swap(m_getArr + i, m_getArr + i + m_decArr[i]);
}
return m_getArr;
}
A few things to notice. First, the algorithm is designed as an object. Although it does not have a state to keep, it does have array, or memory, accounting to do. Second, upper boundary check is made on account of the following observation: The indices ranges from 

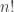
Concerning its time complexity. Our input is an array of size n. And all operations inside the get function are shallow loops of size up to n, with constant4 operations in each of them. So we get 
That is it for now about permutations. Tell me what you think.
1Andrew Cooke, whose site I link to above, showed me this. Which says I reached something similar to a “Lehmer code” – which is a translation of the natural numbers to a mixed radix form. What makes it relevant, is that there’s an injective (one-to-one) mapping between the codes and permutations (for a given sequence of some finite size). This means that for a sequence of size n, you could for every number between 0 and n!-1, use Lehmer to create a single and unique permutation. If you looked at the definition of Lehmer code, you’ll see the resemblance to the above algorithm’s way of translating a non negative number into a sequence of transpositions (what I called a “swap”. Look at m_decArr after the second loop), which is also in a mixed radix form. The difference is that Lehmer code does not use transpositions.
2 
3 The 



4 Constant as in very fast. Arithmetic operations are done in